Journal of Fuzzy Systems and Control, Vol. 2, No 3, 2024 |
|
Stacked Learning Anomaly Detection Scheme with Data Augmentation for Spatiotemporal Traffic Flow
Amaka Patience Binitie 1*  , Christopher Chukwufunaya Odiakaose 2, , Margareth Dumebi Okpor 3, ,
, Christopher Chukwufunaya Odiakaose 2, , Margareth Dumebi Okpor 3, ,
Patrick Ogholuwarami Ejeh 4, , Andrew Okonji Eboka 5, , Arnold Adimabua Ojugo 6, ,
De Rosal Ignatius Moses Setiadi 7, , Rita Erhovwo Ako 8, , Tabitha Chukwudi Aghaunor 9, ,
Victor Ochuko Geteloma 10, , Anderson Afotanwo 11,
1,5 Department of Computer, Federal College of Education (Technical) Asaba, Nigeria
2,4 Department of Computer, Dennis Osadebay University, Asaba, Nigeria
3 Department of Cybersecurity, Delta State University of Science and Technology, Ozoro, Nigeria
6,8,10 Department of Computer Science, Federal University of Petroleum Resources, Effurun, Nigeria
7 Department of Informatics Engineering, Dian Nuswantoro University, Semarang, Indonesia
9 Department of Data Intelligence and Tech, Robert Morris University, Pittsburg, Pennsylvania, United States of America
11 Department of Computer, Federal Polytechnic Orogun, Nigeria
Email: 1 amaka.binitie@fcetasaba.edu.ng, 2 osegalaxy@gmail.com, 3 okpormd@dsust.edu.ng, 4 patrick.ejeh@dou.edu.ng,
5 eboka.andrew@fcetasaba.edu.ng, 6 ojugo.arnold@fupre.edu.ng, 7 moses@dsn.dinus.ac.id, 8 rita.ako@fupre.edu.ng,
9 cxast461@mail.rmu.edu, 10 geteloma.victor@fupre.edu.ng, 11 afotanwo.anderson@fepo.edu.ng
*Corresponding Author
Abstract—The digital revolution births transformation in many facets of today’s society. Its adoption in transportation to curb traffic congestion in major cities globally advances smart-city initiatives. Challenges of population growth, lack of datasets, and aging infrastructure have necessitated the need for traffic analytics. Studies have estimated an associated global annual loss of $583 billion to traffic congestion for 2023. This, caused fuel wastage, loss of time, and increased costs across congested areas. With the cost of building more road networks, cities must advance new ways to improve traffic flow via anomaly detection as an early warning in the flow pattern. Our study posits stacked learning with extreme gradient boost as a meta-learner to help address imbalanced datasets, yield faster model construction, and ensure improved performance via enhanced anomalous data detection.
Keywords—Traffic Flow; Anomaly Detection; Machine Learning; XGBoost; Tree-based Algorithms
Introduction
Governments and businesses today often generate a great amount of spatiotemporal data, especially via the transportation of various forms [1] to curb, both the effects of urbanization and to effectively manage her transportation infrastructure [2]. To observe such data (even in its unstructured form), transportation organs utilize sensor units with feedback access to observed data generated in real-time [3][4]. These, have aided data processing with time-location-based constraints to ease migration. It has become both imperative and crucial to store spatiotemporal data, as they have proven to be helpful in the effective management of the transport infrastructure [5][6].
In the quest for ground truth, data mining schemes have yielded evidence as feedback support to decision-making [7]. and in turn, rendered great insights into dimensions for tasks on time and location, which embodies spatiotemporal dataset [7][8]. Domain tasks to benefit from this include hydrology [9][10], epidemiology [11][12], traffic flow management [13], etc. These, heavily depend on spatiotemporal mining methods, deployed as a cost-effective solution aimed to modify traditional mining schemes to yield new strategy that enables gleaning of insightful knowledge [14][15] as a new paradigm, language, and vehicle to communicate ground truth from such spatiotemporal datasets.
The consequent advances and integration of technology in society have continued to upscale urbanization [16]; But, it also makes difficult the use of traditional schemes to detect anomalies from such an unstructured and ambiguous nature of the generated traffic flow dataset [17]. This, in turn, yields degraded prediction in traffic flow data mining. Traffic flow analysis has thus, become a primordial feat aimed at data flow patterns and outlier value detection [18] – to account for the spatial and temporal nature of the dataset used [19][20]. Thus, anomaly identification and detection [21] have become critical features in the classification of traffic flow analysis to aid the effective management of transport infrastructure.
Spatiotemporal Anomaly Detection in Traffic Flow
Spatiotemporal anomaly detection [22] has since become crucial and critical to data mining – aimed at finding a range of abnormalities generated in unstructured dataset's temporal and spatial data [23][24]. With technological advances in transport infrastructure – traffic flow analysis has gained prominence with the adoption of sensor-based networks and global position systems [25][26]. Data mining with spatiotemporal schemes can include trajectory classification [27], flow analysis [28][29], anomaly/outlier detection [30][31], and identification of regular/periodic patterns [32]–[34].
An anomaly is an observation whose data points appear out of the norm, or it presents an offset function of a system from its normal operation [35]. Anomaly detection is grouped into density [36], deviation [37], profile [38], statistical [39], distance [40], and cluster [41] schemes. Traffic flow anomaly detection can utilize machine learning schemes [42] to detect unusual patterns within a dataset; And help resolve issues such as poor generalization, data imbalance, feature selection, prediction performance, etc [43]. Its focal goal is to identify unexpected behaviors that aid saturated states of traffic congestion [44] as contributed to by its varying traffic factors such as aging road structures, population growth, etc.
Machine Learning Anomaly Detection Approaches
Detection tasks have largely been accomplished via the utilization of either classification or regression analysis and modes. Both classification and regression domain tasks are often accomplished via the methods of voting, stacking, and boosting. On these, detection tasks in a more general term can be grouped into three (3) categories: Deep learning (DL) [45], Ensemble Learning (EL) [46], and machine learning (ML) [47]. ML offers a range of heuristics that have achieved great success over time – as they have been successfully trained to effectively recognize evidence to support ground truth for high-dimension problems in complex un(structured) datasets [48]. Their flexibility and robust feat allow them to recognize patterns, using their adaptive learning in feature engineering to decipher crucial parameters to be selected in constructing the model. And thus, eases outlier detection from behavioral norms of data-labels [49]–[51]. Various ML models include Logistic Regression [52][53], Bayes [54], Support Vector [55][56], K-Nearest Neighbors [57], and Fuzzy [58].
Deep Learning (DL) here, refers to those heuristics based on the recurrent neural networks (NN). These are specifically suited to capture high-dimension feats for time-series-based data sequences, which are often found to be common in many complex, chaotic, and non-linear spatiotemporal datasets and for electronic medical health records [59]. By default – RNN-based heuristics are well-suited for spatiotemporal datasets. Its demerit is that it yields poor generalization via its vanishing gradients problem. Its variant, the Long-Short-Term Memory (LSTM) overcomes this via gates, which control data flow so that the heuristic easily adapts to changes experienced as long-term dependencies [60]. Their efficiency requires longer training time and large datasets. Ensemble learning effectively combines ML and DL [61] into a single classifier to yield an optimal solution via stacking, bagging, boosting, and voting schemes – to yield a richer insight into the targeted task domain [62].
For stacking – it trains a meta/higher learner to effectively combine the predictive outcome of several learners, allowing its meta-learner to improve as it learns from the errors of its base classifiers. This flexibility ensures stacking yields better outcomes with more iterations [63]. In voting, the learners are applied independently to achieve a more stable performance with reduced overfit via predictive aggregation in its quest for ground truth. Since it seeks to combine only the final output of all learners without recourse to their predictive relations – in some instances, it yields degraded performance due to its dataset complexity and diversity [64]. Bagging trains similar learners with equal voting weight. To promote variance, each learner is trained using a randomly drawn subset of the train data. It achieves higher accuracy by averaging all learners’ predictions. It can also be configured to use various learners on different populations to reduce the variance error(s) in each learner [65][66]. Lastly. Boost mode sequentially trains its learners so that each new model corrects the errors of its previous model. It yields a series of learner that focus on difficult tasks that their predecessors failed to correctly predict; And results in higher generalization with improved accuracy. A common boost is adaptive boosting. However, to improve this scheme, an ensemble can be based on a gradient scale such as the eXtreme Gradient Boost [67][68].
Study Motivation and Rationale
The study hopes to address these problems [69]–[72]:
- Imbalanced Data: The resultant ensemble(s) will help investigate the effects of both imbalanced datasets on the predictive reliability in all tree-based ensemble(s) as well as the resulting relationship in their predictive outcomes as rendered by the nature of the dataset complexity and diversity. This stacking ensemble approach/scheme will unveil the resultant implication of the various tree-based models on the ensemble's capability to accurately predict anomalous traffic flow analysis, which in turn – helps new researchers and experts glean the much-needed insights knowledge in the context of traffic management in urban metropolis vis-a-vis within the business context.
- Ensemble construction: To yield an efficient, decision support scheme for improved prediction accuracy of the anomalous detection in traffic flow analysis, we adopt the Gradient Boost scheme, designed to capture all the unique, chaotic, and dynamic features that are rippled across the spatiotemporal dataset; And in turn, impacts anomalous behavior in traffic flow patterns and analysis via the use of feature selection.
- Comparative Analysis will yield evaluation of learning schemes vis-à-vis compare studies that have explored the same spatiotemporal dataset in the context of prediction accuracy, performance, reuse, and construction ease – in a bid to identify the most suitable in traffic flow pattern analysis and detection [73][74].
We construct a tree-based boost ensemble – to address dataset imbalance, and yield better generalization, reducing overfit of the model with reduced dimensionality that will aid a faster ensemble construction via careful feature selection; And in turn, assure improved performance accuracy.
Materials and Methods
In ensemble learning, adopting a tree-based model yields a set of if-else rules that explore the majority voting scheme to predict observed classes [75]. Each tree uses the recursive top-down, binary-tree mode that partitions its predictor with data points grouped into classes that are successively more homogeneous [76]. With each tree understood [77], its task predictive ability can lead to model overfit and/or underfit with degraded performance as it learns to identify the feats of interest that will help classify unknown data points as target class during its training [78][79]. Ensembles yield improved performance with reduced risk of overtraining and overfit [80]. To learn, they construct trees [81] that aggregate all three results into one better learner via bagging [82], boost [83][84], stack [85][86], and voting [87][88] mode.
Tree-based ensembles have successfully proven to yield enhanced performance than some established methods across a variety of different tasks as they are better suited to reduce both bias and variance in learning schemes. While individual models may get stuck in local minima [89], the tree-based weighted combination of several different local minima is aggregated and learned from using the ensemble method [90] – to minimize the risk of choosing the wrong local minimum.
Some reasons for our choice of the tree-based algorithm are: (a) each tree votes to decide a classifier’s outcome, (b) it can handle complex data [91], (c) yields improved generalization, (d) reflects the contribution of feature selection for enhanced performance, and (e) is noise-resilient for ground truth even with (un)structured data in real-time applications [92]–[95].
The stacking mode is based on Fig. 1 as follows:
- Step-1 – Data Collection: Input data is read and stored. We used the Kaggle traffic prediction dataset available at [web]: www.kaggle.com/datasets/fedesoriano/traffic-prediction-dataset, which has 48,120 records as in Table 1. Afterwards, the entire dataset was split as thus into 75% for train, and 25% for testing data-subset [96].
- Dataset description for Consumer Subscription
Features | Data-Type | Description |
Time | Time | Time the sensor observed the input record |
Date | Date | Date the sensor observed the input record |
Junction | Object | Location in time for which data was observed |
Vehicles | Integer | The type of vehicle that was observed as a junction |
ID | Numeric | Car registration details are coded using an ID tag |
Number | Object | Registered number assigned by a state to a vehicle |
Color | Char | Vehicle color as registered to a state |
State | Char | State of origin where a vehicle was first registered |
State ID | Char | State and city code the vehicle was assigned to |
- Step 2 – Data Cleaning deletes missing labels to ensure data quality, and removes duplicate labels to ensure it is devoid of redundancies. Also, we encode the dataset by converting it from non-numeric to its numeric equivalent values using the principal component analysis (PCA).
- Step 3 – Feature Selection and Extraction: Selection helps us to select and extract what labels become input (X), and determine what label will that ensemble predict as output (Y). Thus, it removes all docile feats with no importance to our target class, which in turn helps us to reduce the dimensionality of the chosen dataset [97] and fasten ensemble construction for improved performance [98][99] especially in cases where cost is a critical factor [100]. Efficiency in selected features is evaluated on how well the ensemble fits [101] about ground truth or target class [102]. We use a recursive feat elimination wrapper since our feats are engineered to unveil how relevant a selected feature supports our target class, and test via frequency distribution to ascertain how its occurrence fits with the target class [103][104]. With our computed threshold value of 0.8991 – we have a total of 5 features extracted from the original dataset. We thus selected chi-square values for attributes related to ground truth or target class 1 (i.e., anomaly) as in Table 2 [105]. These were examined to help us gain insights into the contribution of different features to the classification process [106][107].
- Ranking of Features Engineered using Wrapper Mode
Features | Data Type | Ranking | Selected (Yes/No) |
Time | Time | 0.9805 | Yes |
Date | Date | 0.9318 | Yes |
Vehicles | Integer | 0.9016 | Yes |
Plate_No | Object | 0.7432 | No |
Vehicle_ID | Numeric | 0.9291 | Yes |
Vehicle_Color | Char | 0.6590 | No |
State_Registered | Char | 0.5391 | No |
State_ID | Char | 0.3528 | No |
Junction | Object | 0.9241 | Yes |
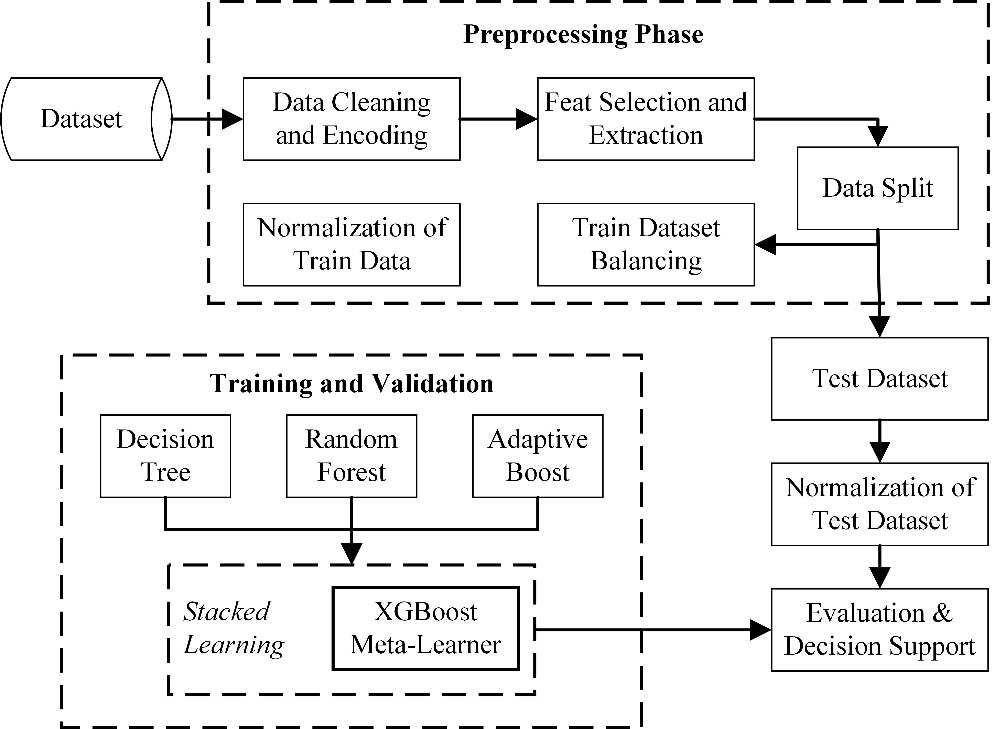
- Proposed Stacking Ensemble Approach with XGBoost as Meta-heuristics
- Step-4 – Data Split helps us track cum improve each feature value towards our target class. The dataset is split into the train (70%) and test (30%) subsets for this study. There is no rule as to how they can be grouped.
- Step-5 Balancing redistributes points in the train dataset after splitting and ensures an almost equal distribution of its class(es) (minor and major). There are a variety of modes, But we consider augmentation modes such as:
- SMOTE: Synthetic over-sample technique performs balancing as thus: (a) identifies minor-class and adjusts data to those of its closest neighbors, (b) interpolates to create synthetic data, and (c) adds the generated synthetic data to the original dataset to yield a balanced dataset classes distribution [108] as in Fig. 2(a) and Fig. 2(b) respectively.

|
(a) |

|
(b) |
- (a) Original bata plot and (b) Data balancing with SMOTE applied
- SMOTE-Edited Nearest Neighbors (SMOTEEN) combines over-and-under-sample feats. It identifies and links data to the closest neighbor(s) [109]. It creates new data points to populate the minor class, and randomly removes from the majority class, to resolve imbalance via the closest neighbor [110] in Fig. 3.

- Data balancing via SMOTEEN
- SMOTE-Tomek balances class distribution via the SMOTE. It also uses the Tomek-link mode under-sampling of a majority class, and to potentially create overlapping classes [95] as in Fig. 4.

- Data balancing via SMOTE-Tomek
We choose the SMOTE-Tomek method since it generates the best situation for the data balancing and provides a good fit for multiple base classifiers.
- Step-5 – Normalization allows us to use the variable transformation to normalize the skewed dataset. This seeks to ensure a nearness in the class distribution and may result in a change in our data distribution. Features are normalized via a standard scaler, which seeks to revert data features to yield a distribution that has a mean value of 0 and a standard deviation of 1. We achieve this via the Equation (1) as thus:
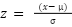
| (1) |
 is the original value,
is the original value,  is the mean,
is the mean,  is the standard deviation, and
is the standard deviation, and  is our normalization process.
is our normalization process.
Stacked Ensembles and Model Construction
Stacked learning seeks to combine the predictive outcome of several base learners to acquire or achieve a more accurate prediction. It often involves 2-levels for which the first level consists of base learners (in this case, Adaptive Boosting, Decision trees, and Random Forest), and the second level aggregates the predictions of the first-level learners usually called a meta-heuristic/learner (in this case, the XGBoost). Its major merits include: (a) the diversification of models via the use of several algorithms [111], (b) enhanced generalization for the resulting model [112], and (c) reduced risk in the overfitting of the ensemble [113]. The selection of a meta-learner is critical and crucial as they must be able to optimize the aggregated outputs and efficiently minimize prediction errors. The right meta-learner (especially for one) trained using the out-of-fold prediction from the base classifiers can significantly improve the ensemble accuracy, flexibility, and robustness – effectively harnessing the processing prowess of multiple good-fit base classifiers [114].
Tree-based ensemble approaches adopted here include:
- Decision Tree is a single-classifier that explores intricate sampling, tailored to mitigate the decision-making issues [115][116]. To predict a target class, it starts from its root node to compare the values of the root with the records attribute. With this compared, it branches off to the next node as (a) begins at a tree with root node S that consists of a complete dataset, (b) finds the best attribute in the dataset via attribute selection measure, (c) divides S into train/test sub-datasets that contains possible values for the best attributes, (d) generate decision tree node, which contains best attributes, and (e) recursively make new decision trees using the subset of the dataset created [117]. Then continue this process until the criterion for optimal solution is reached so that the tree can no longer classify the nodes. Such is reached by leaf node via error pruning and/or cost-complex pruning. Its demerits are: (i) it is complex due to its many layers, (ii) may result in overfit, resolved via a Random Forest ensemble, and (c) computational complexity increases for large datasets [118]. Furthermore, its merits are numerous and the feats used in our DT construction are as in Table 3.
- The Decision Tree Classifier Design
Features | Value | Details |
info_gain | 120 | Number of trees constructed |
learning_rate | 0.25 | Step size learning to update ensemble |
min_sample_split | 10 | Minimal number of samples needed |
min_sample_leaf | auto | Number of features to be considered in place of ground-truth |
eval_set | (x,val, y_val) | Dataset used for evaluating ensemble performance at training |
min_weight_fraction_leaf | 0.1 | Determines tree’s structure based on the weight assigned to each sample |
max_depth | 5 | Max depth of each tree |
random_state | 25 | The seeds for reproduction |
- Random Forest ensemble utilizes the bagging mode to grow successive trees independently can be seen in Table 4. It uses bootstrap aggregation to construct each tree and to sample its train data using a majority vote at its prediction [119]. The RF extends this randomness via an extra layer that changes how it constructs its trees. With a tree, each node is split using the binary-tree predictor – RF splits its nodes and randomly selects the best predictor node from its subset of learner(s) [120]. Its recursive structure helps it to capture interactions between various predictors [121]. Its drawback is in its flexibility [122][123] with data diversity and complexity [124] as its outcome can yield lesser performance [125] for ground truth. To curb this, we adopt hyper-parameter tuning to greatly reduce model overfit, address imbalanced datasets, and enhance accuracy in its quest for ground truth [126][127].
- The Random Forest Ensemble Design
Features | Value | Details |
n_estimators | 150 | Number of trees constructed |
learning_rate | 0.25 | Step size learning for update |
max_depth | 5 | Max depth of each tree |
max_features | 5 | Maximum number of features to construct the RF tree ensemble |
min_sample_leaf | auto | Number of feats to be considered |
min_sample_split | 10 | Minimal samples needed |
min_weight_fraction_leaf | 0.1 | Tree’s structure based on weight assigned to each sample |
random_state | 25 | The seeds for reproduction |
eval_metric | error, logloss | Performance evaluation metrics |
eval_set | x,val, y_val | Train data for evaluation |
verbose | True | Determines if ensemble evaluation metric is printed at training |
bootstrap | True | Ensures bootstrap aggregation use |
warm_start | False | Ensure the tree does not restart |
- Adaptive Boosting combines multiple weak classifiers to build a strong one can be seen in Table 5. Weak learners are called decision stumps as they are DTs with a single split. The ensemble places more weight on hard-to-classify instances and less weight on data operating well. Stumps are produced for every feature iteratively and stored in a list until a lower error is received. The weight (s) assigned to each example determines its significance in the training dataset. Weights are updated with each iteration to yield stumps’ performance. Ensemble sequentially trains its predictors so that each predictor tries to correct its predecessor [128]. Thus, they are more robust against overfitting and yield a more stable and improved performance.
- The AdaBoost Ensemble Design
Features | Value | Details |
n_estimators | 140 | Number of trees constructed |
learning_rate | 0.25 | Step size learning to update the ensemble |
max_depth | 5 | Max depth of each tree |
random_state | 25 | The seeds for reproduction |
eval_metric | [“error’, ‘logloss’] | Evaluation metrics for ensemble performance |
eval_set | (x,val, y_val) | Dataset used for evaluating ensemble performance at training |
verbose | True | Determines if ensemble evaluation metric is printed at training |
- XGBoost is a tree-based leaner that scales the gradient-boosting [129] to classify data points can be seen in Table 6. It yields a stronger classifier by aggregating its weaker (base) learner tree via majority voting schemes over a series of iterations on data points to yield an optimal fit solution. It expands its goal function by minimizing its loss function as Equation (2) to yield an improved model to manage tree complexity more effectively [130]. For optimality – the XGBoost leverages the predictive power of weak base learners, to yield a better decision tree with each iteration and account for the weak performance that contributes to its knowledge about the task [131]. Thus, with each tree trained on the candidate data, it expands the objective function via a regularization term
 and loss function
and loss function  to ensure an appropriate fit of the ensemble to yield improved generalization. This ensures that both training dataset fits as a re-calibrated solution to remain within its solution’s set boundaries, and tunes its loss function for higher accuracy [132][133].
to ensure an appropriate fit of the ensemble to yield improved generalization. This ensures that both training dataset fits as a re-calibrated solution to remain within its solution’s set boundaries, and tunes its loss function for higher accuracy [132][133].

| (2) |
- The XGBoost Ensemble Design
Features | Value | Details |
n_estimators | 250 | Number of trees constructed |
learning_rate | 0.25 | Step size learning to update the ensemble |
max_depth | 5 | Max depth of each tree |
random_state | 25 | The seeds for reproduction |
eval_metric | [“error’, ‘logloss’] | Performance evaluation metrics |
eval_set | (x,val, y_val) | Train dataset to evaluate performance |
verbose | True | Determines if ensemble evaluation metric is printed at training |
Training Phase
Ensemble learns from scratch using the training dataset. With tree-based models, its trees are iteratively constructed to allow for bootstrap training of each tree to yield the required enhancement using prediction probabilities on the scaled and balanced dataset. This further enhances the trees' collective knowledge and in turn, helps the ensemble to easily and quickly identify all inherent intricate patterns present in each data set since training blends both the newly created synthetic and original samples in its dataset to guarantee all base-learner comprehensive learning. This improves model flexibility and adaptability for reuse in other domain tasks.
Hyperparameter tuning controls how much of the tree’s complexity and its nodal weights need to be adjusted in place of gradient loss. The lower the value, the slower we travel on a downward slope – which also ensures how quickly a tree abandons old beliefs for new ones during training. So that as the tree learns – it identifies crucial from unimportant feats. Our meta-learner yields a higher learning rate to imply that our tree ensemble changes quickly as it learns newer features. This flexibility grants its adaptability ease. The ensemble uses regularization terms to ensure it quickly changes as values remain within its lower and upper bounds. It does this to ensure it adequately adjusts its learning and avoids poor generalization. Then we carefully tuned these parameters: max_depth, n_estimator, learning_rate, and booster to ensure optimal performance [134].
Cross-validation is applied with 10 percent of the training dataset to estimate how well-learned skills by the ensemble perform on unseen data. It also evaluates the performance of the ensemble’s accuracy on how well it has learned the feats of interest via resampled and balanced dataset technique. We use the stratified k-fold, to rearrange the data so that each fold is a good representation of the dataset [135] and ensure our proposed stacking ensemble is devoid of overfit with improved generalization. We tested our resultant ensemble as an embedded system deployed via Flask application program interface (API) and Streamlit to help port the application onto various platforms as an embedded system.
Result Findings and Discussion
Results Findings and Discussion
Table 7 shows the performance evaluation metrics for all base-learners (Decision Tree, Random Forest, and AdaBoost) respectively with the meta-learner (i.e. XGBoost Regressor). Note that the purpose of the tree-based ensemble learning is to reduce the outcome relations conflict caused therein due to the diversity and computational complexities of the dataset used. And in turn, ensure the ensemble is devoid of overfit considering the 3-base-learners. However, since the stacking ensemble can combine the performance of all 3-predictor classifiers – we decided to ensure simple and non-complex constructs for the tree-based, base-learners used.
- Base Learner Performance Metrics Details
Base-Learners | Accuracy | Precision | Recall | F1 |
DT | 0.9815 | 0.9805 | 0.9745 | 0.9805 |
AdaBoost | 0,9968 | 0.9318 | 0.9848 | 0.9881 |
Random Forest | 0.9981 | 0.9541 | 0.9881 | 0.9925 |
Meta-Learner |
XGBoost | 1.0000 | 1.0000 | 0.9999 | 1.0000 |
Table 7 shows that for our base-tree-classifiers – both the Adaboost and Decision Tree underperformed in comparison to the Random Forest. And this agrees with [90]. However, all 3-base leaners (i.e. DT, RF, and Adaboost) yield training accuracy of 0.9815, 0.9968, and 0.9981 respectively. With Recall score(s) of 0.9745, 0.9848, and 0.9881 respectively; And Precision of 0.9805, 0.9318, and 0.9541 respectively; And F1-score of 0.9805, 0.9881, and 0.9925 respectively. Conversely, the meta-learner yields perfect scores for its Accuracy, Recall, Precision, and F1 respectively. Thus, our ensemble classifies traffic anomaly in spatiotemporal data accurately as detected [136][137] dataset and has proven to efficiently reduce bias and variance as in the confusion matrix of Fig. 5 – yielding a more stable and robust heuristic for new data and/or hidden underlying parameters within the training dataset.

- Confusion Matrix for the Stacking Ensemble
The study supports that SMOTE-Tomek data balancing outperformed both SMOTEEN and SMOTE modes, as it had a greater influence in the quest for ground truth. It greatly impacted the overall performance by identifying features of importance that influence model prediction [138][139]. It also had enhanced efficiency for differentiating between true-positive and true-negative, and between false-positive and false-negative scores [140][141]. Fig. 5 shows the confusion matrix performance.
Comparison
As we explore the high performance of our proposed stacking ensemble across the domain dataset to demonstrate its flexibility, adaptability, robustness, and prediction ability [142] – we also benchmark it against previous methods that have utilized the same or similar dataset. To this end – we found none [143]. Thus, we benchmark our ensemble against similar design constructs on various datasets for various domain tasks as seen in Table 8 [144][145].
- Benchmark / comparative testing of method
Methods | Accuracy | Precision | Recall | F1 | Spec. |
Ref [81] | 0.8728 | 0.8500 | 0.8120 | 0.8925 | 0.9300 |
Ref [95] | 1.0000 | 1.0000 | 0.9999 | 1.0000 | 1.0000 |
Ref [113] | 0.7824 | 0.7631 | 0.7500 | 0.7732 | - |
Ref [146] | 0.7815 | 0.7025 | 0.7372 | 0.7902 | - |
Ref [147] | 0,9968 | 0.9318 | 0.9848 | 0.9881 | 0.8902 |
Ref [148] | 0.9981 | 0.9541 | 0.9881 | 0.9925 | 0.7829 |
Our Method | 1.0000 | 1.0000 | 0.9999 | 1.0000 | 1.0000 |
Whilst some domain task datasets have proven much easier to detect/recognize and classified [149]; Others, have also conversely proven to be more painstaking [150]. Some domain task(s) such as medical and image records – require its chosen ensemble design metric to be strongly impacted by the consequence of diagnostic errors within the captured dataset. Thus, specificity and sensitivity are critical features to be evaluated since they are directly related to the patient clinical outcomes [151][152].
Conclusion
Finding the balance between recall and specificity is also a crucial feat as too much emphasis on one, can ripple across the dataset – to yield a significant tradeoff for the other. In addition, Accuracy can yield the idea of a model’s reliability, which may also be less insightful for imbalanced datasets that in some cases, render distorted perceived model performance [153]. However, in truth and practice – F1 has been utilized in assessing a heuristic’s performance on criteria such as data imbalance – as it has been found to provide an altruist insight into a technique's effectiveness in classifying positive cases without the overprediction of false positives.
In tree-based ensembles – bagging mode at its simplest form, explores majority voting from several independent decision trees to aid its prediction. The boosting approach learns from the errors of its base learner such that each successor tree is sequentially based and/or linked to account for its predecessor's error. We argue that when making a decision, it is better to do it based on experiences from previous mistakes rather than deciding for the first time. This study proves that the use of a stacking ensemble with XGB as a meta-classifier (with its hyper-parameter tuning) can help result in perfect scores for AUC, F1, and other score criteria as required for a great many data mining tasks.
References
- Q. Xie, T. Guo, Y. Chen, Y. Xiao, X. Wang, and B. Y. Zhao, “‘How do urban incidents affect traffic speed?’ A Deep Graph Convolutional Network for Incident-driven Traffic Speed Prediction,” arXiv preprint arXiv:1912.01242, 2019, https://doi.org/10.1145/3340531.3411873.
- R. R. Atuduhor et al., “StreamBoostE: A Hybrid Boosting-Collaborative Filter Scheme for Adaptive User-Item Recommender for Streaming Services,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 10, no. 2, pp. 89–106, 2024, https://doi.org/10.22624/AIMS/V10N2P8.
- F. Zantalis, G. Koulouras, S. Karabetsos, and D. Kandris, “A Review of Machine Learning and IoT in Smart Transportation,” Futur. Internet, vol. 11, no. 4, p. 94, 2019, https://doi.org/10.3390/fi11040094.
- D. Wang, P. Wang, J. Zhou, L. Sun, B. Du, and Y. Fu, “Defending Water Treatment Networks: Exploiting Spatio-Temporal Effects for Cyber Attack Detection,” in 2020 IEEE International Conference on Data Mining (ICDM), pp. 32–41, 2020, https://doi.org/10.1109/ICDM50108.2020.00012.
- D. A. Obasuyi et al., “NiCuSBlockIoT: Sensor-based Cargo Assets Management and Traceability Blockchain Support for Nigerian Custom Services,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 15, no. 2, pp. 45–64, 2024, https://doi.org/10.22624/AIMS/CISDI/V15N2P4.
- S. E. Brizimor et al., “WiSeCart: Sensor-based Smart-Cart with Self-Payment Mode to Improve Shopping Experience and Inventory Management,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 10, no. 1, pp. 53–74, 2024, https://doi.org/10.22624/AIMS/SIJ/V10N1P7.
- A. A. Ojugo et al., “Forging a User-Trust Memetic Modular Neural Network Card Fraud Detection Ensemble: A Pilot Study,” J. Comput. Theor. Appl., vol. 1, no. 2, pp. 1–11, 2023, https://doi.org/10.33633/jcta.v1i2.9259.
- A. A. Ojugo et al., “Evidence of Students’ Academic Performance at the Federal College of Education Asaba Nigeria: Mining Education Data,” Knowl. Eng. Data Sci., vol. 6, no. 2, pp. 145–156, 2023, https://doi.org/10.17977/um018v6i22023p145-156.
- J. Dong et al., “Estimating reference crop evapotranspiration using improved convolutional bidirectional long short-term memory network by multi-head attention mechanism in the four climatic zones of China,” Agric. Water Manag., vol. 292, no. December 2023, p. 108665, 2024, https://doi.org/10.1016/j.agwat.2023.108665.
- L. F. Rahman, M. Marufuzzaman, L. Alam, M. A. Bari, U. R. Sumaila, and L. M. Sidek, “Developing an ensembled machine learning prediction model for marine fish and aquaculture production,” Sustainability, vol. 13, no. 16, p. 9124, 2021, https://doi.org/10.3390/su13169124.
- M. Zhong and R. Ding, “Design of a Personalized Recommendation System for Learning Resources based on Collaborative Filtering,” Int. J. Circuits, Syst. Signal Process., vol. 16, pp. 122–131, 2022, https://doi.org/10.46300/9106.2022.16.16.
- A. A. Ojugo et al., “CoSoGMIR: A Social Graph Contagion Diffusion Framework using the Movement-Interaction-Return Technique,” J. Comput. Theor. Appl., vol. 1, no. 2, pp. 37–47, 2023, https://doi.org/10.33633/jcta.v1i2.9355.
- Y. Lu, P. Kamranfar, D. Lattanzi, and A. Shehu, “Traffic Flow Forecasting with Maintenance Downtime via Multi-Channel Attention-Based Spatio-Temporal Graph Convolutional Networks,” arXiv preprint arXiv:2110.01535, 2021, https://doi.org/10.48550/arXiv.2110.01535.
- M. Y. Ansari, A. Ahmad, S. S. Khan, G. Bhushan, and Mainuddin, “Spatiotemporal clustering: a review,” Artif. Intell. Rev., vol. 53, no. 4, pp. 2381–2423, 2020, https://doi.org/10.1007/s10462-019-09736-1.
- A. Hamdi, K. Shaban, A. Erradi, A. Mohamed, S. K. Rumi, and F. D. Salim, “Spatiotemporal data mining: a survey on challenges and open problems,” Artif. Intell. Rev., vol. 55, no. 2, pp. 1441–1488, 2022, https://doi.org/10.1007/s10462-021-09994-y.
- K. Kalair and C. Connaughton, “Anomaly detection and classification in traffic flow data from fluctuations in the flow–density relationship,” Transp. Res. Part C Emerg. Technol., vol. 127, p. 103178, 2021, https://doi.org/10.1016/j.trc.2021.103178.
- E. U. Omede, A. E. Edje, M. I. Akazue, H. Utomwen, and A. A. Ojugo, “IMANoBAS: An Improved Multi-Mode Alert Notification IoT-based Anti-Burglar Defense System,” J. Comput. Theor. Appl., vol. 1, no. 3, pp. 273–283, 2024, https://doi.org/10.62411/jcta.9541.
- [18] S. Qian et al., “Detecting Taxi Trajectory Anomaly Based on Spatio-Temporal Relations,” IEEE Trans. Intell. Transp. Syst., vol. 23, no. 7, pp. 6883–6894, 2022, https://doi.org/10.1109/TITS.2021.3063199.
- A. A. Ojugo and O. D. Otakore, “Computational solution of networks versus cluster grouping for social network contact recommender system,” Int. J. Informatics Commun. Technol., vol. 9, no. 3, p. 185, 2020, https://doi.org/10.11591/ijict.v9i3.pp185-194.
- A. A. Ojugo, E. Ugboh, C. C. Onochie, A. O. Eboka, M. O. Yerokun, and I. J. Iyawa, “Effects of Formative Test and Attitudinal Types on Students’ Achievement in Mathematics in Nigeria,” African Educ. Res. J., vol. 1, no. 2, pp. 113–117, 2013, https://eric.ed.gov/?id=EJ1216962.
- D. R. I. M. Setiadi, A. Susanto, K. Nugroho, A. R. Muslikh, A. A. Ojugo, and H. Gan, “Rice yield forecasting using hybrid quantum deep learning model,” MDPI Comput., vol. 13, no. 191, pp. 1–18, 2024, https://doi.org/10.3390/computers13080191.
- Y. Hao, J. Li, N. Wang, X. Wang, and X. Gao, “Spatiotemporal consistency-enhanced network for video anomaly detection,” Pattern Recognit., vol. 121, p. 108232, 2022, https://doi.org/10.1016/j.patcog.2021.108232.
- A. A. Ojugo and A. O. Eboka, “Modeling Behavioural Evolution as Social Predictor for the Coronavirus Contagion and Immunization in Nigeria,” J. Appl. Sci. Eng. Technol. Educ., vol. 3, no. 2, pp. 135–144, 2021, https://doi.org/10.35877/454RI.asci130.
- B. O. Malasowe, M. I. Akazue, A. E. Okpako, F. O. Aghware, D. V. Ojie, and A. A. Ojugo, “Adaptive Learner-CBT with Secured Fault-Tolerant and Resumption Capability for Nigerian Universities,” Int. J. Adv. Comput. Sci. Appl., vol. 14, no. 8, pp. 135–142, 2023, https://doi.org/10.14569/IJACSA.2023.0140816.
- D. A. Oyemade and A. A. Ojugo, “A property oriented pandemic surviving trading model,” Int. J. Adv. Trends Comput. Sci. Eng., vol. 9, no. 5, pp. 7397–7404, 2020, https://doi.org/10.30534/ijatcse/2020/71952020.
- A. Boukerche and J. Wang, “Machine Learning-based traffic prediction models for Intelligent Transportation Systems,” Comput. Networks, vol. 181, p. 107530, 2020, https://doi.org/10.1016/j.comnet.2020.107530.
- C. Xu and Y. Xie, “Conformal Anomaly Detection on Spatio-Temporal Observations with Missing Data,” arXiv preprint arXiv:2105.11886 , 2021, https://doi.org/10.48550/arXiv.2105.11886.
- A. Emami, M. Sarvi, and S. A. Bagloee, “Short-term traffic flow prediction based on faded memory Kalman Filter fusing data from connected vehicles and Bluetooth sensors,” Simul. Model. Pract. Theory, vol. 102, p. 102025, 2020, https://doi.org/10.1016/j.simpat.2019.102025.
- C. Ren et al., “Short-Term Traffic Flow Prediction: A Method of Combined Deep Learnings,” J. Adv. Transp., vol. 2021, pp. 1–15, 2021, https://doi.org/10.1155/2021/9928073.
- A. A. Ojugo and A. O. Eboka, “Assessing Users Satisfaction and Experience on Academic Websites: A Case of Selected Nigerian Universities Websites,” Int. J. Inf. Technol. Comput. Sci., vol. 10, no. 10, pp. 53–61, 2018, https://doi.org/10.5815/ijitcs.2018.10.07.
- A. R. Muslikh, D. R. I. M. Setiadi, and A. A. Ojugo, “Rice disease recognition using transfer xception convolution neural network,” J. Tek. Inform., vol. 4, no. 6, pp. 1541–1547, 2023, https://doi.org/10.52436/1.jutif.2023.4.6.1529.
- H. Yuan and G. Li, “A Survey of Traffic Prediction: from Spatio-Temporal Data to Intelligent Transportation,” Data Sci. Eng., vol. 6, no. 1, pp. 63–85, 2021, https://doi.org/10.1007/s41019-020-00151-z.
- L. Erhan et al., “Smart anomaly detection in sensor systems: A multi-perspective review,” Inf. Fusion, vol. 67, pp. 64–79, 2021, https://doi.org/10.1016/j.inffus.2020.10.001.
- A. A. Ojugo and A. O. Eboka, “Modeling the Computational Solution of Market Basket Associative Rule Mining Approaches Using Deep Neural Network,” Digit. Technol., vol. 3, no. 1, pp. 1–8, 2018, https://doi.org/10.11591/ijict.v8i3.pp128-138.
- A. B. Nassif, M. A. Talib, Q. Nasir, and F. M. Dakalbab, “Machine Learning for Anomaly Detection: A Systematic Review,” IEEE Access, vol. 9, pp. 78658–78700, 2021, https://doi.org/10.1109/ACCESS.2021.3083060.
- A. A. Ojugo and O. Nwankwo, “Multi-Agent Bayesian Framework For Parametric Selection In The Detection And Diagnosis of Tuberculosis Contagion In Nigeria,” JINAV J. Inf. Vis., vol. 2, no. 2, pp. 69–76, 2021, https://doi.org/10.35877/454RI.jinav375.
- C. Zoremsanga and J. Hussain, "Particle Swarm Optimized Deep Learning Models for Rainfall Prediction: A Case Study in Aizawl, Mizoram," in IEEE Access, vol. 12, pp. 57172-57184, 2024, https://doi.org/10.1109/ACCESS.2024.3390781.
- B. Medina-Salgado, E. Sánchez-DelaCruz, P. Pozos-Parra, and J. E. Sierra, “Urban traffic flow prediction techniques: A review,” Sustain. Comput. Informatics Syst., vol. 35, p. 100739, 2022, https://doi.org/10.1016/j.suscom.2022.100739.
- M. Huang, W. Liu, T. Wang, H. Song, X. Li, and A. Liu, “A queuing delay utilization scheme for on-path service aggregation in services-oriented computing networks,” IEEE Access, vol. 7, pp. 23816–23833, 2019, https://doi.org/10.1109/ACCESS.2019.2899402.
- X. Tang, K. An, K. Guo, Y. Huang, and S. Wang, “Outage analysis of non-orthogonal multiple access-based integrated satellite-terrestrial relay networks with hardware impairments,” IEEE Access, vol. 7, no. September, pp. 141258–141267, 2019, https://doi.org/10.1109/ACCESS.2019.2944406.
- A. A. Ojugo and R. E. Yoro, “Migration Pattern As Threshold Parameter In The Propagation of The Covid-19 Epidemic Using An Actor-Based Model for SI-Social Graph,” JINAV J. Inf. Vis., vol. 2, no. 2, pp. 93–105, 2021, https://doi.org/10.35877/454RI.jinav379.
- A. A. Ojugo and O. Nwankwo, “Modeling Mobility Pattern for the Corona-Virus Epidemic Spread Propagation and Death Rate in Nigeria using the Movement-Interaction-Return Model,” Int. J. Emerg. Trends Eng. Res., vol. 9, no. 6, pp. 821–826, 2021, https://doi.org/10.30534/ijeter/2021/30962021.
- Y. Bouchlaghem, Y. Akhiat, and S. Amjad, “Feature Selection: A Review and Comparative Study,” E3S Web Conf., vol. 351, pp. 1–6, 2022, https://doi.org/10.1051/e3sconf/202235101046.
- S. Wang, J. Cao, and P. S. Yu, “Deep Learning for Spatio-Temporal Data Mining: A Survey,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 8, pp. 3681–3700, 2022, https://doi.org/10.1109/TKDE.2020.3025580.
- J. Yao, C. Wang, C. Hu, and X. Huang, “Chinese Spam Detection Using a Hybrid BiGRU-CNN Network with Joint Textual and Phonetic Embedding,” Electronics, vol. 11, no. 15, p. 2418, 2022, https://doi.org/10.3390/electronics11152418.
- A. A. Ojugo and A. O. Eboka, “Inventory prediction and management in Nigeria using market basket analysis associative rule mining: memetic algorithm based approach,” Int. J. Informatics Commun. Technol., vol. 8, no. 3, p. 128, 2019, https://doi.org/10.11591/ijict.v8i3.pp128-138.
- C. H. Lee, H. C. Yang, Y. C. Wei, and W. K. Hsu, “Enabling blockchain based scm systems with a real time event monitoring function for preemptive risk management,” Appl. Sci., vol. 11, no. 11, 2021, https://doi.org/10.3390/app11114811.
- T. Muralidharan and N. Nissim, “Improving malicious email detection through novel designated deep-learning architectures utilizing entire email,” Neural Networks, vol. 157, pp. 257-279, 2023, https://doi.org/10.1016/j.neunet.2022.09.002.
- S. Basterrech and M. Wozniak, “Tracking changes using Kullback-Leibler divergence for the continual learning,” in 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 3279–3285, 2022, https://doi.org/10.1109/SMC53654.2022.9945547.
- A. A. Ojugo, C. O. Obruche, and A. O. Eboka, “Quest For Convergence Solution Using Hybrid Genetic Algorithm Trained Neural Network Model For Metamorphic Malware Detection,” ARRUS J. Eng. Technol., vol. 2, no. 1, pp. 12–23, 2021, https://doi.org/10.35877/jetech613.
- A. A. Ojugo, C. O. Obruche, and A. O. Eboka, “Empirical Evaluation for Intelligent Predictive Models in Prediction of Potential Cancer Problematic Cases In Nigeria,” ARRUS J. Math. Appl. Sci., vol. 1, no. 2, pp. 110–120, 2021, https://doi.org/10.35877/mathscience614.
- E. Ileberi, Y. Sun, and Z. Wang, “A machine learning based credit card fraud detection using GA algorithm for feature selection,” J. Big Data, vol. 9, no. 1, p. 24, 2022, https://doi.org/10.1186/s40537-022-00573-8.
- I. Benchaji, S. Douzi, B. El Ouahidi, and J. Jaafari, “Enhanced credit card fraud detection based on attention mechanism and LSTM deep model,” J. Big Data, vol. 8, no. 1, p. 151, 2021, https://doi.org/10.1186/s40537-021-00541-8.
- L. E. Mukhanov, “Using bayesian belief networks for credit card fraud detection,” Proc. IASTED Int. Conf. Artif. Intell. Appl. AIA 2008, no. February 2008, pp. 221–225, 2008, https://www.actapress.com/Abstract.aspx?paperId=32306.
- A. P. Binitie and O. J. Babatunde, “Evaluating the privacy issues, potential risks, and security measures associated with using social media platforms,” Int. J. African Res. Sustain. Stud., vol. 3, no. 2, pp. 167–179, 2024, https://cambridgeresearchpub.com/ijarss/article/view/139.
- J. Herdiansyah, F. Ariefka, S. Putra, and D. Septiyanto, “Implementation of Zhang ’ s Camera Calibration Algorithm on a Single Camera for Accurate Pose Estimation Using ArUco Markers,” J. Fuzzy Syst. Control, vol. 2, no. 3, pp. 176–188, 2024, https://doi.org/10.59247/jfsc.v2i3.256.
- E. A. L. Marazqah Btoush, X. Zhou, R. Gururajan, K. C. Chan, R. Genrich, and P. Sankaran, “A systematic review of literature on credit card cyber fraud detection using machine and deep learning,” PeerJ Comput. Sci., vol. 9, p. e1278, 2023, https://doi.org/10.7717/peerj-cs.1278.
- A. S. Ali, E. H. Ali, S. W. Shneen, and L. H. Abood, “Adaptive Fuzzy Filter Technique for Mixed Noise Removing from Sonar Images Underwater,” J. Fuzzy Syst. Control, vol. 2, no. 2, pp. 45–49, 2024, https://doi.org/10.59247/jfsc.v2i2.176.
- A. A. Ojugo and O. Nwankwo, “Tree-classification Algorithm to Ease User Detection of Predatory Hijacked Journals: Empirical Analysis of Journal Metrics Rankings,” Int. J. Eng. Manuf., vol. 11, no. 4, pp. 1–9, 2021, https://doi.org/10.5815/ijem.2021.04.01.
- H. Huang, Y. Song, Z. Fan, G. Xu, R. Yuan, and J. Zhao, “Estimation of walnut crop evapotranspiration under different micro-irrigation techniques in arid zones based on deep learning sequence models,” Results Appl. Math., vol. 20, no. September, p. 100412, 2023, https://doi.org/10.1016/j.rinam.2023.100412.
- M. I. Akazue et al., “FiMoDeAL: pilot study on shortest path heuristics in wireless sensor network for fire detection and alert ensemble,” Bull. Electr. Eng. Informatics, vol. 13, no. 5, pp. 3534–3543, 2024, https://doi.org/10.11591/eei.v13i5.8084.
- A. A. Ojugo, P. O. Ejeh, C. C. Odiakaose, A. O. Eboka, and F. U. Emordi, “Predicting rainfall runoff in Southern Nigeria using a fused hybrid deep learning ensemble,” Int. J. Informatics Commun. Technol., vol. 13, no. 1, p. 108, 2024, https://doi.org/10.11591/ijict.v13i1.pp108-115.
- D. R. I. M. Setiadi, G. A. Trisnapradika, W. Herowati, and H. M. M. Islam, “Analyzing Preprocessing Impact on Machine Learning Classifiers for Cryotherapy and Immunotherapy Dataset,” J. Futur. Artif. Intell. Technol., vol. 1, no. 1, pp. 1–16, 2024, https://doi.org/10.62411/faith.2024-2.
- M. D. Okpor et al., “Comparative Data Resample to Predict Subscription Services Attrition Using Tree-based Ensembles,” J. Fuzzy Syst. Control, vol. 2, no. 2, pp. 117–128, 2024, https://doi.org/10.59247/jfsc.v2i2.213.
- E. B. Wijayanti, D. R. I. M. Setiadi, and B. H. Setyoko, “Dataset Analysis and Feature Characteristics to Predict Rice Production based on eXtreme Gradient Boosting,” J. Comput. Theor. Appl., vol. 2, no. 1, pp. 79–90, 2024, https://doi.org/10.62411/jcta.10057.
- A. Suruliandi, G. Mariammal, and S. P. Raja, “Crop prediction based on soil and environmental characteristics using feature selection techniques,” Math. Comput. Model. Dyn. Syst., vol. 27, no. 1, pp. 117–140, 2021, https://doi.org/10.1080/13873954.2021.1882505.
- F. Omoruwou, A. A. Ojugo, and S. E. Ilodigwe, “Strategic Feature Selection for Enhanced Scorch Prediction in Flexible Polyurethane Form Manufacturing,” J. Comput. Theor. Appl., vol. 1, no. 3, pp. 346–357, 2024, https://doi.org/10.62411/jcta.9539.
- C. Singha and K. C. Swain, “Rice crop growth monitoring with sentinel 1 SAR data using machine learning models in google earth engine cloud,” Remote Sens. Appl. Soc. Environ., vol. 32, p. 101029, 2023, https://doi.org/10.1016/j.rsase.2023.101029.
- M. Shehab, A. T. Khader, and M. A. Al-Betar, “A survey on applications and variants of the cuckoo search algorithm,” Applied soft computing, vol. 61, pp. 1041-1059, 2017, https://doi.org/10.1016/j.asoc.2017.02.034.
- B. N. Supriya and C. B. Akki, “Sentiment prediction using enhanced xgboost and tailored random forest,” Int. J. Comput. Digit. Syst., vol. 10, no. 1, pp. 191–199, 2021, https://doi.org/10.12785/ijcds/100119.
- S. Meghana, B. . Charitha, S. Shashank, V. S. Sulakhe, and V. B. Gowda, “Developing An Application for Identification of Missing Children and Criminal Using Face Recognition.,” Int. J. Adv. Res. Comput. Commun. Eng., vol. 12, no. 6, pp. 272–279, 2023, https://doi.org/10.17148/IJARCCE.2023.12648.
- Sharmila, R. Sharma, D. Kumar, V. Puranik, and K. Gautham, “Performance Analysis of Human Face Recognition Techniques,” Proc. - 2019 4th Int. Conf. Internet Things Smart Innov. Usages, IoT-SIU 2019, no. May 2020, pp. 1–4, 2019, https://doi.org/10.1109/IoT-SIU.2019.8777610.
- A. A. Ojugo, R. A. Abere, B. C. Orhionkpaiyo, R. E. Yoro, and A. O. Eboka, “Technical Issues for IP-Based Telephony in Nigeria,” Int. J. Wirel. Commun. Mob. Comput., vol. 1, no. 2, p. 58, 2013, https://doi.org/10.11648/j.wcmc.20130102.11.
- L. D. S. B. Weerasinghe, R. M. J. C. K. Rajaguru, A. G. Jayasundara and D. K. Wickramanayeke, "Design and implementing VoIP network in the national defence university of Sri Lanka," SoutheastCon 2015, pp. 1-2, 2015, https://doi.org/10.1109/SECON.2015.7133030.
- M. K. Elmezughi, O. Salih, T. J. Afullo, and K. J. Duffy, “Comparative Analysis of Major Machine-Learning-Based Path Loss Models for Enclosed Indoor Channels,” Sensors, vol. 22, no. 13, p. 4967, 2022, https://doi.org/10.3390/s22134967.
- D. Kilroy, G. Healy, and S. Caton, “Using Machine Learning to Improve Lead Times in the Identification of Emerging Customer Needs,” IEEE Access, vol. 10, pp. 37774–37795, 2022, https://doi.org/10.1109/ACCESS.2022.3165043.
- F. Safara, “A Computational Model to Predict Consumer Behaviour During COVID-19 Pandemic,” Comput. Econ., vol. 59, no. 4, pp. 1525–1538, 2022, https://doi.org/10.1007/s10614-020-10069-3.
- K. Muhamada, D. R. Ignatius, M. Setiadi, U. Sudibyo, B. Widjajanto, and A. A. Ojugo, “Exploring Machine Learning and Deep Learning Techniques for Occluded Face Recognition: A Comprehensive Survey and Comparative Analysis,” J. Futur. Artif. Intell. Technol., vol. 1, no. 2, pp. 160–173, 2024, https://doi.org/10.62411/faith.2024-30.
- V. O. Geteloma et al., “Enhanced data augmentation for predicting consumer churn rate with monetization and retention strategies : a pilot study,” Appl. Eng. Technol., vol. 3, no. 1, pp. 35–51, 2024, https://doi.org/10.31763/aet.v3i1.1408.
- A. A. Ojugo and E. O. Ekurume, “Deep Learning Network Anomaly-Based Intrusion Detection Ensemble For Predictive Intelligence To Curb Malicious Connections: An Empirical Evidence,” Int. J. Adv. Trends Comput. Sci. Eng., vol. 10, no. 3, pp. 2090–2102, 2021, https://doi.org/10.30534/ijatcse/2021/851032021.
- L. Shen, Y. Bao, N. Hasan, Y. Huang, X. Zhou, and C. Deng, “Intelligent crude oil price probability forecasting: Deep learning models and industry applications,” Computers in Industry, vol. 163, p. 104150, 2024, https://doi.org/10.1016/j.compind.2024.104150.
- C. Li et al., “Improvement of wheat grain yield prediction model performance based on stacking technique,” Applied Sciences, vol. 11, no. 24, p. 12164, 2021, https://doi.org/10.3390/app112412164.
- C. Bentéjac, A. Csörgő, and G. Martínez-Muñoz, “A comparative analysis of gradient boosting algorithms,” Artificial Intelligence Review, vol. 54, pp. 1937-1967, 2021, https://doi.org/10.1007/s10462-020-09896-5.
- N. M. Shahani, X. Zheng, C. Liu, F. U. Hassan, and P. Li, “Developing an XGBoost Regression Model for Predicting Young’s Modulus of Intact Sedimentary Rocks for the Stability of Surface and Subsurface Structures,” Front. Earth Sci., vol. 9, 2021, https://doi.org/10.3389/feart.2021.761990.
- K. Vaishnavi, U. N. Kamath, B. A. Rao, and N. V. S. Reddy, “Predicting Mental Health Illness using Machine Learning Algorithms,” J. Phys. Conf. Ser., vol. 2161, no. 1, 2022, https://doi.org/10.1088/1742-6596/2161/1/012021.
- O. Jaiyeoba, E. Ogbuju, O. T. Yomi, and F. Oladipo, “Development of a Model to Classify Skin Diseases using Stacking Ensemble Machine Learning Techniques,” J. Comput. Theor. Appl., vol. 2, no. 1, pp. 22–38, 2024, https://doi.org/10.62411/jcta.10488.
- K. Deepika, M. P. S. Nagenddra, M. V. Ganesh, and N. Naresh, “Implementation of Credit Card Fraud Detection Using Random Forest Algorithm,” Int. J. Res. Appl. Sci. Eng. Technol., vol. 10, no. 3, pp. 797–804, 2022, https://doi.org/10.22214/ijraset.2022.40702.
- M. Reza Rezvan, A. Ghanbari Sorkhi, J. Pirgazi, and M. Mehdi Pourhashem Kallehbasti, “AdvanceSplice: Integrating N-gram one-hot encoding and ensemble modeling for enhanced accuracy,” Biomed. Signal Process. Control, vol. 92, no. August 2023, p. 106017, 2024, https://doi.org/10.1016/j.bspc.2024.106017.
- J. K. Oladele et al., “BEHeDaS: A Blockchain Electronic Health Data System for Secure Medical Records Exchange,” J. Comput. Theor. Appl., vol. 1, no. 3, pp. 231–242, 2024, https://doi.org/10.62411/jcta.9509.
- F. O. Aghware et al., “Enhancing the Random Forest Model via Synthetic Minority Oversampling Technique for Credit-Card Fraud Detection,” J. Comput. Theor. Appl., vol. 1, no. 4, pp. 407–420, 2024, https://doi.org/10.62411/jcta.10323.
- L. Gauder, L. Pepino, P. Riera, S. Brussino, J. Vidal, A. Gravano, and L. Ferrer, “A Study on the manifestation of trust in speech,” arXiv preprint arXiv:2102.09370, 2021, https://doi.org/10.48550/arXiv.2102.09370.
- B. O. Malasowe, A. E. Okpako, M. D. Okpor, P. O. Ejeh, A. A. Ojugo, and R. E. Ako, “FePARM: The Frequency-Patterned Associative Rule Mining Framework on Consumer Purchasing-Pattern for Online Shops,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 15, no. 2, pp. 15–28, 2024, https://doi.org/10.22624/AIMS/CISDI/V15N2P2-1.
- B. O. Malasowe, D. V. Ojie, A. A. Ojugo, and M. D. Okpor, “Co-infection prevalence of Covid-19 underlying tuberculosis disease using a susceptible infect clustering Bayes Network,” Dutse J. Pure Appl. Sci., vol. 10, no. 2a, pp. 80–94, 2024, https://doi.org/10.4314/dujopas.v10i2a.8.
- A. N. Safriandono, D. R. I. M. Setiadi, A. Dahlan, F. Z. Rahmanti, I. S. Wibisono, and A. A. Ojugo, “Analyzing Quantum Feature Engineering and Balancing Strategies Effect on Liver Disease Classification,” J. Futur. Artif. Intell. Technol., vol. 1, no. 1, pp. 51–63, 2024, https://doi.org/10.62411/faith.2024-12.
- D. R. I. M. Setiadi, K. Nugroho, A. R. Muslikh, S. W. Iriananda, and A. A. Ojugo, “Integrating SMOTE-Tomek and Fusion Learning with XGBoost Meta-Learner for Robust Diabetes Recognition,” J. Futur. Artif. Intell. Technol., vol. 1, no. 1, pp. 23–38, 2024, https://doi.org/10.62411/faith.2024-11.
- M. I. Akazue et al., “Handling Transactional Data Features via Associative Rule Mining for Mobile Online Shopping Platforms,” Int. J. Adv. Comput. Sci. Appl., vol. 15, no. 3, pp. 530–538, 2024, https://doi.org/10.14569/IJACSA.2024.0150354.
- H. Lu and C. Rakovski, “The Effect of Text Data Augmentation Methods and Strategies in Classification Tasks of Unstructured Medical Notes,” Res. Sq., vol. 1, no. 1, pp. 1–29, 2022, https://doi.org/10.21203/rs.3.rs-2039417/v1.
- M. Bayer, M. A. Kaufhold, B. Buchhold, M. Keller, J. Dallmeyer, and C. Reuter, “Data augmentation in natural language processing: a novel text generation approach for long and short text classifiers,” Int. J. Mach. Learn. Cybern., vol. 14, no. 1, pp. 135–150, 2023, https://doi.org/10.1007/s13042-022-01553-3.
- A. A. Ojugo et al., “Forging a learner-centric blended-learning framework via an adaptive content-based architecture,” Sci. Inf. Technol. Lett., vol. 4, no. 1, pp. 40–53, 2023, https://doi.org/10.31763/sitech.v4i1.1186.
- O. V. Lee et al., “A malicious URLs detection system using optimization and machine learning classifiers,” Indones. J. Electr. Eng. Comput. Sci., vol. 17, no. 3, p. 1210, 2020, https://doi.org/10.11591/ijeecs.v17.i3.pp1210-1214.
- S. N. Okofu et al., “Pilot Study on Consumer Preference, Intentions and Trust on Purchasing-Pattern for Online Virtual Shops,” Int. J. Adv. Comput. Sci. Appl., vol. 15, no. 7, pp. 804–811, 2024, https://doi.org/10.14569/IJACSA.2024.0150780.
- R. K. Rachman, D. R. I. M. Setiadi, A. Susanto, K. Nugroho, and H. M. M. Islam, “Enhanced Vision Transformer and Transfer Learning Approach to Improve Rice Disease Recognition,” J. Comput. Theor. Appl., vol. 1, no. 4, 2024, https://doi.org/10.62411/jcta.10459.
- A. Taravat and F. Del Frate, “Weibull Multiplicative Model and Machine Learning Models for Full-Automatic Dark-Spot Detection From Sar Images,” Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci., vol. XL-1/W3, no. September 2013, pp. 421–424, 2013, https://doi.org/10.5194/isprsarchives-XL-1-W3-421-2013.
- K. P. Parmar and T. Bhatt, "Crop Yield Prediction based on Feature Selection and Machine Learners: A Review," 2022 Second International Conference on Artificial Intelligence and Smart Energy (ICAIS), pp. 354-358, 2022, https://doi.org/10.1109/ICAIS53314.2022.9742891.
- A. A. Ojugo and A. O. Eboka, “Empirical Bayesian network to improve service delivery and performance dependability on a campus network,” IAES Int. J. Artif. Intell., vol. 10, no. 3, p. 623, 2021, https://doi.org/10.11591/ijai.v10.i3.pp623-635.
- A. M. Ifioko et al., “CoDuBoTeSS: A Pilot Study to Eradicate Counterfeit Drugs via a Blockchain Tracer Support System on the Nigerian Frontier,” J. Behav. Informatics, Digit. Humanit. Dev. Res., vol. 10, no. 2, pp. 53–74, 2024, https://doi.org/10.22624/AIMS/BIHIV10N1P6.
- P. Charoen-Ung and P. Mittrapiyanuruk, “Sugarcane Yield Grade Prediction Using Random Forest with Forward Feature Selection and Hyper-parameter Tuning,” 2019, pp. 33–42, 2019, https://doi.org/10.1007/978-3-319-93692-5_4.
- P. O. Ejeh et al., “Counterfeit Drugs Detection in the Nigeria Pharma-Chain via Enhanced Blockchain-based Mobile Authentication Service,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 12, no. 2, pp. 25–44, 2024, https://doi.org/10.22624/AIMS/MATHS/V12N2P3.
- B. Pavlyshenko and M. Stasiuk, “Data augmentation in text classification with multiple categories,” Electron. Inf. Technol., vol. 25, p. 749, 2024, https://doi.org/10.30970/eli.25.6.
- M. D. Okpor et al., “Pilot Study on Enhanced Detection of Cues over Malicious Sites Using Data Balancing on the Random Forest Ensemble,” J. Futur. Artif. Intell. Technol., vol. 1, no. 2, pp. 109–123, 2024, https://doi.org/10.62411/faith.2024-14.
- A. A. Ojugo and A. O. Eboka, “Empirical Evidence of Socially-Engineered Attack Menace Among Undergraduate Smartphone Users in Selected Universities in Nigeria,” Int. J. Adv. Trends Comput. Sci. Eng., vol. 10, no. 3, pp. 2103–2108, 2021, https://doi.org/10.30534/ijatcse/2021/861032021.
- S. Rajendran and P. Jayagopal, “Accessing Covid19 epidemic outbreak in Tamilnadu and the impact of lockdown through epidemiological models and dynamic systems,” Measurement, vol. 169, p. 108432, 2021, https://doi.org/10.1016/j.measurement.2020.108432.
- N. N. Wijaya, D. R. I. M. Setiadi, and A. R. Muslikh, “Music-Genre Classification using Bidirectional Long Short-Term Memory and Mel-Frequency Cepstral Coefficients,” J. Comput. Theor. Appl., vol. 2, no. 1, pp. 13–26, 2024, https://doi.org/10.62411/jcta.9655.
- D. Nguyen et al., “Adaptive Evaluation of LQR Control using Particle Swarm Optimization for Pendubot,” J. Fuzzy Syst. Control, vol. 2, no. 2, pp. 58–66, 2024, https://doi.org/10.59247/jfsc.v2i2.203.
- S. Kumar, N. A. Jailani, A. R. Singh and S. Panchal, "Sentiment Analysis on Online Reviews using Machine Learning and NLTK," 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), pp. 1183-1189, 2022, https://doi.org/10.1109/ICOEI53556.2022.9776850.
- R. E. Ako et al., “Effects of Data Resampling on Predicting Customer Churn via a Comparative Tree-based Random Forest and XGBoost,” J. Comput. Theor. Appl., vol. 2, no. 1, pp. 86–101, 2024, https://doi.org/10.62411/jcta.10562.
- V. Umarani, A. Julian, and J. Deepa, “Sentiment Analysis using various Machine Learning and Deep Learning Techniques,” J. Niger. Soc. Phys. Sci., vol. 3, no. 4, pp. 385–394, 2021, https://doi.org/10.46481/jnsps.2021.308.
- F. Jáñez-Martino, E. Fidalgo, S. González-Martínez, and J. Velasco-Mata, “Classification of Spam Emails through Hierarchical Clustering and Supervised Learning,” Natl. Cybersecurity Inst., vol. 24, pp. 1–4, 2020, https://doi.org/10.48550/arXiv.2005.08773.
- A. Satpathi et al., “Comparative Analysis of Statistical and Machine Learning Techniques for Rice Yield Forecasting for Chhattisgarh, India,” Sustainability, vol. 15, no. 3, p. 2786, 2023, https://doi.org/10.3390/su15032786.
- A. Bahl et al., “Recursive feature elimination in random forest classification supports nanomaterial grouping,” NanoImpact, vol. 15, p. 100179, 2019, https://doi.org/10.1016/j.impact.2019.100179.
- C. L. Udeze, I. E. Eteng, and A. E. Ibor, “Application of Machine Learning and Resampling Techniques to Credit Card Fraud Detection,” J. Niger. Soc. Phys. Sci., vol. 12, p. 769, 2022, https://doi.org/10.46481/jnsps.2022.769.
- Y. Abakarim, M. Lahby, and A. Attioui, “An Efficient Real Time Model For Credit Card Fraud Detection Based On Deep Learning,” in International Conference on Intelligent Systems, 2018, pp. 1–7, 2018, https://doi.org/10.1145/3289402.3289530.
- M. Zareapoor and P. Shamsolmoali, “Application of Credit Card Fraud Detection: Based on Bagging Ensemble Classifier,” Procedia Comput. Sci., vol. 48, pp. 679–685, 2015, https://doi.org/10.1016/j.procs.2015.04.201.
- S. Xuan, G. Liu, Z. Li, L. Zheng, S. Wang, and C. Jiang, “Random forest for credit card fraud detection,” in 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), pp. 1–6, 2018, https://doi.org/10.1109/ICNSC.2018.8361343.
- N. Rtayli and N. Enneya, “Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization,” J. Inf. Secur. Appl., vol. 55, p. 102596, 2020, https://doi.org/10.1016/j.jisa.2020.102596.
- A. A. Ojugo and A. O. Eboka, “An Empirical Evaluation On Comparative Machine Learning Techniques For Detection of The Distributed Denial of Service (DDoS) Attacks,” J. Appl. Sci. Eng. Technol. Educ., vol. 2, no. 1, pp. 18–27, 2020, https://doi.org/10.35877/454RI.asci2192.
- S. Saponara, A. Elhanashi, and A. Gagliardi, “Real-time video fire/smoke detection based on CNN in antifire surveillance systems,” J. Real-Time Image Process., vol. 18, no. 3, pp. 889–900, 2021, https://doi.org/10.1007/s11554-020-01044-0.
- E. A. Otorokpo et al., “DaBO-BoostE: Enhanced Data Balancing via Oversampling Technique for a Boosting Ensemble in Card-Fraud Detection,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 12, no. 2, pp. 45–66, 2024, https://doi.org/10.22624/AIMS/MATHS/V12N2P4.
- S. Paliwal, A. K. Mishra, R. K. Mishra, N. Nawaz, and M. Senthilkumar, “XGBRS Framework Integrated with Word2Vec Sentiment Analysis for Augmented Drug Recommendation,” Comput. Mater. Contin., vol. 72, no. 3, pp. 5345–5362, 2022, https://doi.org/10.32604/cmc.2022.025858.
- A. A. Ojugo, P. O. Ejeh, C. C. Odiakaose, A. O. Eboka, and F. U. Emordi, “Improved distribution and food safety for beef processing and management using a blockchain-tracer support framework,” Int. J. Informatics Commun. Technol., vol. 12, no. 3, p. 205, 2023, https://doi.org/10.11591/ijict.v12i3.pp205-213.
- D. A. Al-Qudah, A. M. Al-Zoubi, P. A. Castillo-Valdivieso, and H. Faris, “Sentiment analysis for e-payment service providers using evolutionary extreme gradient boosting,” IEEE Access, vol. 8, pp. 189930–189944, 2020, https://doi.org/10.1109/ACCESS.2020.3032216.
- B. Habib and F. Khursheed, “Performance evaluation of machine learning models for distributed denial of service attack detection using improved feature selection and hyper‐parameter optimization techniques,” Concurrency and Computation: Practice and Experience, vol. 34, no. 26, p. e7299, 2022, https://doi.org/10.1002/cpe.7299.
- E. Blancaflor, H. K. S. Billo, B. Y. P. Saunar, J. M. P. Dignadice and P. T. Domondon, "Penetration assessment and ways to combat attack on Android devices through StormBreaker - a social engineering tool," 2023 6th International Conference on Information and Computer Technologies (ICICT), pp. 220-225, 2023, https://doi.org/10.1109/ICICT58900.2023.00043.
- Z. Karimi, M. Mansour Riahi Kashani, and A. Harounabadi, “Feature Ranking in Intrusion Detection Dataset using Combination of Filtering Methods,” Int. J. Comput. Appl., vol. 78, no. 4, pp. 21–27, 2013, https://doi.org/10.5120/13478-1164.
- J. Camargo and A. Young, “Feature Selection and Non-Linear Classifiers: Effects on Simultaneous Motion Recognition in Upper Limb,” IEEE Trans. Neural Syst. Rehabil. Eng., vol. 27, no. 4, pp. 743–750, 2019, https://doi.org/10.1109/TNSRE.2019.2903986.
- F. O. Aghware et al., “BloFoPASS: A blockchain food palliatives tracer support system for resolving welfare distribution crisis in Nigeria,” Int. J. Informatics Commun. Technol., vol. 13, no. 2, p. 178, 2024, https://doi.org/10.11591/ijict.v13i2.pp178-187.
- M. J. Madhurya, H. L. Gururaj, B. C. Soundarya, and K. P. Vidyashree, and A. B. Rajendra, “Exploratory analysis of credit card fraud detection using machine learning techniques,” Global Transitions Proceedings, vol. 3, no. 1, pp. 31-37, 2022, https://doi.org/10.1016/j.gltp.2022.04.006.
- J. Johnen and D. Ronayne, “The only dance in town: Unique equilibrium in a generalized model of price competition,” The Journal of Industrial Economics, vol. 69, no. 3, pp. 595-614, 2021, https://doi.org/10.1111/joie.12264.
- D. A. Oyemade, R. J. Ureigho, F. A.-A. Imouokhome, E. U. Omoregbee, J. Akpojaro, and A. A. Ojugo, “A Three Tier Learning Model for Universities in Nigeria,” J. Technol. Soc., vol. 12, no. 2, pp. 9–20, 2016, https://doi.org/10.18848/2381-9251/CGP/v12i02/9-20.
- M. K. G. Roshan, “Multiclass Medical X-ray Image Classification using Deep Learning with Explainable AI,” Int. J. Res. Appl. Sci. Eng. Technol., vol. 10, no. 6, pp. 4518–4526, 2022, https://doi.org/10.22214/ijraset.2022.44541.
- A. D. Bhavani and N. Mangla, “A Novel Network Intrusion Detection System Based on Semi-Supervised Approach for IoT,” Int. J. Adv. Comput. Sci. Appl., vol. 14, no. 4, pp. 207–216, 2023 https://doi.org/10.14569/IJACSA.2023.0140424.
- M. Jameaba, “Digitization, FinTech Disruption, and Financial Stability: The Case of the Indonesian Banking Sector,” SSRN Electron. J., vol. 34, pp. 1–44, 2020, https://doi.org/10.2139/ssrn.3529924.
- S. Pavithra and K. Venkata Vikas, "Detecting Unbalanced Network Traffic Intrusions With Deep Learning," in IEEE Access, vol. 12, pp. 74096-74107, 2024, https://doi.org/10.1109/ACCESS.2024.3405187.
- A. Jović, K. Brkić, N. Bogunović, A. Jovic, K. Brkic, and N. Bogunovic, “A review of feature selection methods with applications,” 2015 38th Int. Conv. Inf. Commun. Technol. Electron. Microelectron. MIPRO 2015 - Proc., pp. 1200–1205, 2015, https://doi.org/10.1109/MIPRO.2015.7160458.
- Y. H. Chang and M. S. Lee, “Incorporating Markov decision process on genetic algorithms to formulate trading strategies for stock markets,” Applied Soft Computing, vol. 52, pp. 1143-1153, 2017, https://doi.org/10.1016/j.asoc.2016.09.016.
- A. A. Ojugo and I. P. Okobah, “Prevalence Rate of Hepatitis-B Virus Infection in the Niger Delta Region of Nigeria using a Graph-Diffusion Heuristic Model,” Int. J. Comput. Appl., vol. 179, no. 39, pp. 975–8887, 2018, https://doi.org/10.5120/ijca2018916585.
- A. A. Ojugo, D. A. Oyemade, R. E. Yoro, A. O. Eboka, M. O. Yerokun, and E. Ugboh, “A Comparative Evolutionary Models for Solving Sudoku,” Autom. Control Intell. Syst., vol. 1, no. 5, p. 113, 2013, https://doi.org/10.11648/j.acis.20130105.13.
- S. Srinivasulu and A. Jain, “A comparative analysis of training methods for artificial neural network rainfall–runoff models,” Applied Soft Computing, vol. 6, no. 3, pp. 295-306, 2006, https://doi.org/10.1016/j.asoc.2005.02.002.
- B. O. Malasowe et al., “Quest for Empirical Solution to Runoff Prediction in Nigeria via Random Forest Ensemble: Pilot Study,” Adv. Multidiscip. Sci. Res. J. Publ., vol. 10, no. 1, pp. 73–90, 2024, https://doi.org/10.22624/AIMS/BHI/V10N1P8.
- F. U. Emordi et al., “TiSPHiMME: Time Series Profile Hidden Markov Ensemble in Resolving Item Location on Shelf Placement in Basket Analysis,” Digit. Innov. Contemp. Res. Sci., vol. 12, no. 1, pp. 33–48, 2024, https://doi.org/10.22624/AIMS/DIGITAL/V11N4P3.
- C. Ma, H. Wang, and S. C. Hoi, “Multi-label thoracic disease image classification with cross-attention networks,” In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part VI 22, pp. 730-738, 2020, https://doi.org/10.1007/978-3-030-32226-7_81.
- V. O. Geteloma et al., “AQuaMoAS: unmasking a wireless sensor-based ensemble for air quality monitor and alert system,” Appl. Eng. Technol., vol. 3, no. 2, pp. 86–101, 2024, https://doi.org/10.31763/aet.v3i2.1536.
- C. C. Odiakaose et al., “Hybrid Genetic Algorithm Trained Bayesian Ensemble for Short Messages Spam Detection,” J. Adv. Math. Comput. Sci., vol. 12, no. 1, pp. 37–52, 2024, https://doi.org/10.22624/AIMS/MATHS/V12N1P4.
Amaka Patience Binitie, Stacked Learning Anomaly Detection Scheme with Data Augmentation for Spatiotemporal Traffic Flow